Streaming Database: 6 Key Components, Uses & Design Principles to Keep in Mind
Due to the increasing expansion of data from non-traditional sources such as IoT sensors, security logs, and web apps, streaming data is becoming a vital component of business data architecture.
Although streaming technologies are not new, they have advanced significantly in recent years. From tedious integration of open-source Spark/Hadoop frameworks to full-stack solutions that enable an end-to-end streaming data architecture built on the scalability of cloud data lakes, the industry is advancing.
What is Streaming Data and Streaming data Architecture?
Data that is continually created, generally in large volumes and at a high rate, is referred to as streaming data. A streaming data source is typically made up of a stream of logs that capture events as they occur, such as a user clicking on a link on a web or a sensor reporting the current temperature.
The following are some instances of streaming data:
- IoT sensors
- Server and security logs
- Real-time advertising
- Click-stream data from apps and websites
We have end devices that are continually creating hundreds of millions of records, forming a data stream — unstructured or semi-structured, most typically JSON or XML key-value pairs – in all of these scenarios. Here's an example of a single streaming event - in this case, we're looking at data from a website session.
Every minute, a single streaming source will create vast volumes of these events. This data is difficult to work within its raw form since it lacks schema and structure, making it difficult to query using SQL-based analytic tools; instead, data must be processed, parsed, and structured before any significant analysis can be conducted.
Streaming Data Architecture
A streaming data architecture is a software framework for ingesting and processing massive amounts of streaming data from many sources. While traditional data solutions focused on writing and reading data in batches, a streaming data architecture consumes data as it is created, persists it to storage, and may include additional components depending on the use case, such as real-time processing, data manipulation, and analytics tools.
Data streams create huge volumes of data (terabytes to petabytes), which is at best semi-structured and requires extensive pre-processing and ETL to become relevant. Streaming systems must be able to account for these particular properties.
Stream processing is a complicated problem that is seldom handled with a single database or ETL tool, necessitating the use of multiple building blocks to 'design' a solution. Many of these building blocks may be merged and replaced with declarative functions inside the Kafka streams platform, and we'll show how this approach expresses itself within each part of the streaming data supply chain.
Why Streaming Data Architecture? Benefits of Stream Processing
Stream processing was once considered a "niche" technology, employed by only a limited number of businesses. With the fast expansion of SaaS, IoT, and machine learning, feet from all sectors are increasingly dabbling in streaming analytics. It's difficult to find a modern firm that doesn't have a mobile app or a website; as traffic for complicated and real-time analytics develops, the necessity for modern data infrastructure is swiftly becoming ubiquitous.
While traditional batch architectures may suffice at lesser sizes, stream processing offers several advantages that other data platforms do not:
- Able to deal with never-ending streams of events—This is how some data is organically structured. Traditional batch processing tools entail interrupting the stream of events, gathering batches of data, and integrating the batches to conclude. While combining and capturing data from multiple streams is difficult in stream processing, it allows you to gain instant insights from massive volumes of streaming data.
- Real-time or near-real-time processing—To allow real-time data analytics, most organizations use stream processing. While high-performance database systems can do real-time analytics, the data is typically better possible to a stream processing architecture.
- Detecting patterns in time-series data—Detecting patterns over time, such as trends in website traffic data, necessitates constant data processing and analysis. Because batch processing divides data into batches, certain events are split across two or more batches, making this more difficult.
- Easy data scalability—Growing data volumes can cause a batch processing system to fail, necessitating the addition of more resources or changes to the architecture. Modern stream processing infrastructure is hyper-scalable, allowing a single stream processor to deal with Gigabytes of data per second. This helps you to deal with growing data volumes without having to modify your infrastructure.
The Components of a Streaming Architecture
The majority of streaming stacks are still made up of open-source and proprietary solutions to specific challenges including stream processing, storage, data integration, and real-time analytics. We've built a modern platform at Kafka streams that integrates the majority of the building blocks and provides a simple way to turn streams into analytics-ready information. For more information, see our technical white paper.
Your streaming architecture must have these four important building blocks, whether you choose a modern data lake platform or a traditional patchwork of tools:
1. The Message Broker / Stream Processor
This is the component that receives data from a producer, converts it to a standard message format, and streams it continuously. Other components can then listen in on the broker's communications and consume them.
The Message Oriented Middleware (MOM) paradigm was used by the initial generation of message brokers, such as RabbitMQ and Apache ActiveMQ. Later, hyper-fast communications platforms (sometimes called stream processors) arose, which are better suited to the streaming paradigm. Apache Kafka and Amazon Kinesis Data Streams are two prominent stream processing tools.
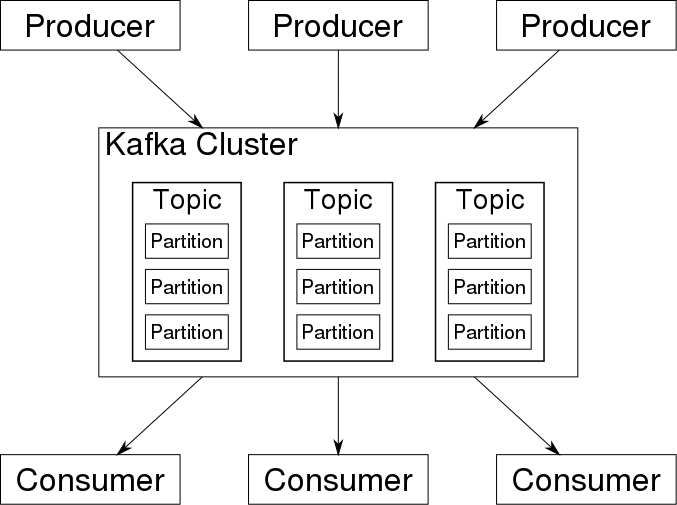
Unlike old MoM brokers, streaming brokers support very high performance with persistence, have massive message traffic capacity of a Gigabyte per second or more, and are tightly focused on streaming with little support for data transformations or task scheduling (although Confluent's KSQL allows for basic ETL in real-time while storing data in Kafka).
More on message brokers may be found in our post on analyzing Apache Kafka data, as well as this comparison of Kafka and RabbitMQ and Apache Kafka with Amazon Kinesis.
2. Batch and Real-time ETL tools
Before data can be evaluated with SQL-based analytics tools, data streams from one or more message brokers must be gathered, transformed, and structured. An ETL tool or platform would achieve this by receiving queries from users, fetching events from message queues, and applying the query to get a result – frequently with further joins, transformations, and aggregations on the data. An API call, an action, a visualization, an alert, or, in certain circumstances, a new data stream may be the result.
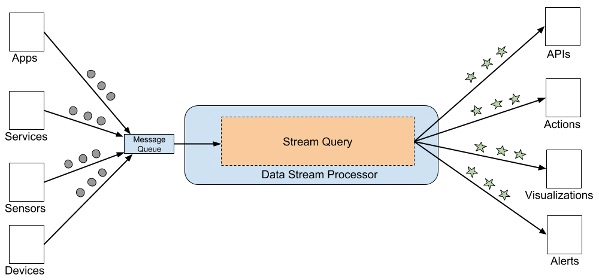
Image Source: InfoQ
Apache Storm, Spark Streaming, and WSO2 Stream Processor are three open-source ETL tools for streaming data. While these frameworks work in different ways, they are all capable of listening to message streams, processing data, and storing it.
Some stream processors, such as Spark and WSO2, include SQL syntax for accessing and processing data; nonetheless, most operations would write complicated Java or Scala code. kafka streams' data lake ETL is designed to give users a self-service solution for converting streaming data using only SQL and a visual interface, without the hassle of coordinating and maintaining ETL tasks in Spark. You can sign up for a free trial here.
3. Data Analytics / Serverless Query Engine
After the stream processor has prepared the data for consumption, it must be examined to offer value. Streaming data analytics may be approached in a variety of ways. Here are some of the most popular streaming data analytics tools.
Analytics Tool
Streaming Use Case
Example Setup
Streaming data is saved to S3. You can set up ad hoc SQL queries via the AWS Management Console, Athena runs them as serverless functions and returns results.
Data warehouse
Amazon Kinesis Streaming Data Firehose Redshift may be used to preserve streaming data. This allows you to perform near-real-time analytics using the BI tools and dashboards you've previously set up with Redshift.
Topics may be streamed directly into Elasticsearch using Kafka Connect. Elasticsearch mappings with the necessary data types are built automatically if you utilize the Avro data format and a schema registry. Within Elasticsearch, you can then execute quick text search or analytics.
Kafka Streams can be processed and stored in a Cassandra cluster. Another Kafka instance may be set up to accept a stream of Cassandra updates and send them to applications for real-time decision-making.
4. Streaming Data Storage
Most organizations are now storing their streaming event data due to the development of low-cost storage technologies. Here are some options for storing streaming data, along with its benefits and pros.
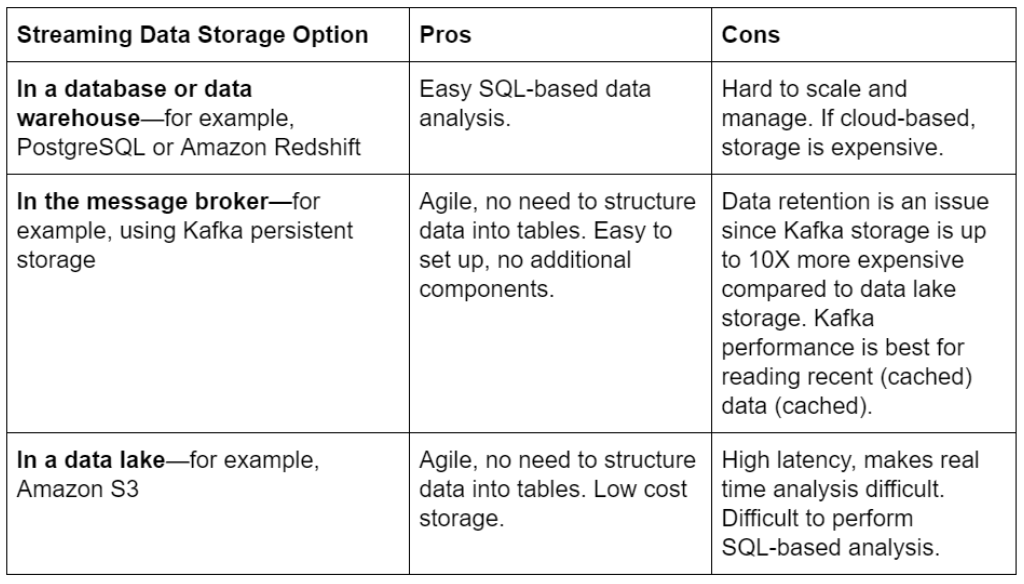
A data lake is the most flexible and cost-effective solution for storing event data, but building and maintaining one is frequently quite technical. The issues of building a data lake and sustaining lake storage best practices, such as ensuring exactly-once processing, partitioning the data, and permitting backfill with historical data, have been written previously. It's simple to dump all of your data into object storage; but, constructing a functioning data lake may be far more difficult.
Modern Streaming Architecture
Many organizations are choosing a complete stack approach to modern streaming data installations rather than patching together open-source technologies. The complexity of traditional architecture is abstracted into a single self-service platform that turns event streams into analytics-ready data in the modern data platform, which is built on business-centric value chains rather than IT-centric coding procedures.
Kafka streams' goal is to serve as a centralized data platform that automates the time-consuming aspects of working with streaming data, such as message ingestion, batch and streaming ETL, storage management, and data preparation for analytics.
Benefits of a modern streaming architecture:
- Can be used to replace major data engineering projects.
- Built-in performance, high availability, and fault tolerance
- Newer platforms are cloud-based and may be quickly implemented with no upfront costs.
- Flexibility and support for multiple ranges of applications
Examples of modern streaming architectures on AWS
Because most of our clients work with streaming data, we come across a variety of streaming use cases, most of which revolve around operationalizing Kafka/Kinesis streams in the Amazon cloud. The case studies and reference architectures listed below will help you understand how companies in various sectors construct their streaming architectures:
Conclusion
To see how many of our forecasts for streaming data trends were correct, read more of our predictions here, or check out some of our other articles on cloud architecture and other streaming data topics.

